
cpp note
字符串
操作符字符串化(#)& 符号连接操作符 (##)
|
关键字
volatile
- 并行设备的硬件寄存器
- 存储器映射的硬件寄存器通常加volatile,因为寄存器随时可以被外设硬件修改。当声明指向设备寄存器的指针时一定要用volatile,它会告诉编译器不要对存储在这个地址的数据进行假设。
- 一个中断服务程序中修改的供其他程序检测的变量
- volatile提醒编译器,它后面所定义的变量随时都有可能改变。因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。
- 多线程应用中被几个任务共享的变量
- 简单地说就是防止编译器对代码进行优化.比如:对外部硬件而言,上述四条语句分别表示不同的操作,会产生四种不同的动作,但是编译器却会对上述四条语句进行优化,认为只有XBYTE[2]=0x58(即忽略前三条语句,只产生一条机器代码)。如果键入volatile,编译器会逐一的进行编译并产生相应的机器代码(产生四条代码)
XBYTE[2]=0x55;
XBYTE[2]=0x56;
XBYTE[2]=0x57;
XBYTE[2]=0x58;
内存
cxx
在cxx中, 虚拟内存分为代码段、数据段、BSS段、堆区、文件映射区以及栈区六部分 :
代码段:包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。
数据段:存储程序中已初始化的全局变量和静态变量
BSS段:存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。
堆区:调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。
映射区:存储动态链接库以及调用mmap函数进行的文件映射
栈:使用栈空间存储函数的返回地址、参数、局部变量、返回值
常用函数
select & poll & epoll
select
int select(int maxfdp,fd_set *readfds,fd_set *writefds,fd_set *errorfds,struct timeval *timeout); |
单个进程能够监听的文件描述符的数量有限制,在1024,也可以在内核中修改
就绪的fd采用轮询的方式扫描:
- select返回的是int,可以理解为返回的是ready(准备好的)一个或者多个文件描述符, 应用程序需要遍历整个文件描述符数组才能发现哪些fd句柄发生了事件,由于select 采用轮询的方式扫描文件描述符(不知道那个文件描述符读写数据,所以需要把所有 的fd都遍历),文件描述符数量越多,性能越差
- select每次都会改变内核中的句柄数据结构集(fd集合),因而每次调用select都需要从 用户空间向内核空间复制所有的句柄数据结构(fd集合),产生巨大的开销
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符 进行IO操作,那么之后每次调用select还是会将这些文件描述符通知进程。
poll
触发方式和select一样,只是抛弃了select 用户态和内核态数据拷贝的位图,改用一个结构体数组(pollfd 链表结构),poll 没有了 1024 的并发连接限制,只要内存够大,支持几十万个连接都没问题。
epoll
调用顺序
int epoll_create(int size); |
首先创建一个epoll对象,然后使用epoll_ctl对这个对象进行操作,把需要监控的描述符添加进去,这些描述符将会以epoll_event结构体的形式组成一颗红黑树,接着阻塞在epoll_wait,进入大循环,当某个fd上有事件发生时,内核将会把其对应的结构体放入到一个链表中,返回有事件发生的链表。
回调机制(红黑树 + 就绪链表)
epoll 的水平触发(LT)模式
状态:这是 epoll 的默认模式。
表现:和 select / poll 完全一样。只要缓冲区还有数据,每次调用 epoll_wait() 都会返回该事件。
优点:应用层写起来安全、简单,不容易漏掉数据。epoll 的边缘触发(ET)模式
状态:通过在注册事件时添加 EPOLLET 标志启用。
表现:只有在文件描述符的状态发生变化时(即从“不可读”变为“可读”,或有新数据到达),epoll_wait 才会通知一次。 如果程序这次没把数据读完,哪怕缓冲区里还剩 1000 个字节,下一次调用 epoll_wait 也绝对不会再通知你。
fork & wait & exec
父进程产生子进程使用fork拷贝出来一个父进程的副本,此时只拷贝了父进程的页 表,两个进程都读同一块内存,当有进程写的时候使用写实拷贝机制分配内存,exec 函数可以加载一个elf文件去替换父进程,从此父进程和子进程就可以运行不同的程序 了。fork从父进程返回子进程的pid,从子进程返回0.调用了wait的父进程将会发生阻 塞,直到有子进程状态改变,执行成功返回0,错误返回-1。exec执行成功则子进程从 新的程序开始运行,无返回值,执行失败返回-1。
fork 创建一个当前进程的副本(子进程),exec 让这个子进程穿上新衣服去执行新程序,而 wait 则是父进程用来给子进程“收尸”(回收资源)的。
硬件基础
nand flash & nor flash
| 特性 / 指标 | NOR Flash | NAND Flash |
|---|---|---|
| 存储容量 | 较小(通常 1MB ~ 512MB) | 极大(目前可达几百 GB 甚至几 TB) |
| 生产成本 / 价格 | 极高(结构复杂,芯片面积大) | 极低(高密度,单位成本极低) |
| 随机读取速度 | 极快 | 较慢(需要先寻址和传输整页) |
| 写入/擦除速度 | 极慢 | 极快 |
| 基本读写单位 | 字节(Byte)级别随机读写 | 页(Page)读写,块(Block)擦除 |
| XIP(芯片内执行) | 支持(代码可以直接在闪存内运行) | 不支持(必须拷贝到 RAM 中运行) |
| 擦写寿命(P/E) | 约 10 万次 | 约几千次(靠主控算法做磨损均衡) |
| 坏块率 | 极低,出厂基本无坏块 | 出厂即自带坏块,使用中会产生新坏块 |
XIP(芯片内执行)
这是 NOR Flash 最引以为傲的杀手锏。由于它可以按字节寻址,CPU 的指令指针可以直接指向 NOR Flash 内部的地址来执行代码,不需要先将代码加载到系统的运行内存(RAM)中。这不仅省去了漫长的“开机加载”时间,还能省下昂贵的 RAM 芯片。
DRAM & SRAM
DRAM: 动态随机存取内存,靠电容存电,比如SSD
SRAM: 静态随机存取内存,比如CPU缓存
- 靠“双稳态触发器”锁死:
- 结构:它不需要电容,而是使用 4 到 6 个晶体管 组成一个“双稳态锁存电路”(触发器)。
- 为什么叫静态:只要通着电,它内部的电路状态就会像一把物理锁一样,死死地扣在 0 或 1 的状态,绝对不会漏电,也完全不需要任何“刷新”动作。
CPU,MPU,MCU,SOC,SOPC
1.CPU(Central Processing Unit),是一台计算机的运算核心和控制核心。CPU由运 算器、控制器和寄存器及实现它们之间联系的数据、控制及状态的总线构成。差不多所有的CPU的运作原理可分为四个阶段:提取(Fetch)、解码(Decode)、执行(Execute)和写回(Writeback)。 CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码,并执行指令。所谓的计算机的可编程性主要是指对CPU的编程。
2.MPU (Micro Processor Unit),叫微处理器(不是微控制器),通常代表一个功能强大的CPU(暂且理解为增强版的CPU吧),但不是为任何已有的特定计算目的而设计的芯片。这种芯片往往是个人计算机和高端工作站的核心CPU。最常见的微处理器是Motorola的68K系列和Intel的X86系列。
3.MCU(Micro Control Unit),叫微控制器,是指随着大规模集成电路的出现及其发展,将计算机的CPU、RAM、ROM、定时计数器和多种I/O接口集成在一片芯片上,形成芯片级的芯片,比如51,avr这些芯片,内部除了CPU外还有RAM,ROM,可 以直接加简单的外围器件(电阻,电容)就可以运行代码了,而MPU如x86,arm这些就不能直接放代码了,它只不过是增强版的CPU,所以得添加RAM,ROM。MCU MPU 最主要的区别就睡能否直接运行代码。MCU有内部的RAM ROM,而MPU是增强版的CPU,需要添加外部RAM ROM才可以运行代码。
4.SOC(System on Chip),指的是片上系统,MCU只是芯片级的芯片,而SOC是系统级的芯片,它既像MCU(51,avr)那样有内置RAM,ROM同时又像MPU(arm) 那样强大的,不单单是放简单的代码,可以放系统级的代码,也就是说可以运行操作系统(将就认为是MCU集成化与MPU强处理力各优点二合一)
5.SOPC(System On a Programmable Chip)可编程片上系统(FPGA就是其中一种),上面4点的硬件配置是固化的,就是说51单片机就是51单片机,不能变为avr,而avr就是avr不是51单片机,他们的硬件是一次性掩膜成型的,能改的就是软件配置,说白点就是改代码,本来是跑流水灯的,改下代码,变成数码管,而SOPC则是硬件配置,软件配置都可以修改,软件配置跟上面一样,没什么好说的,至于硬件,是可以自己构建的也就是说这个芯片是自己构造出来的,这颗芯片我们叫“白片”,什么芯片都不是,把硬件配置信息下载进去了,他就是相应的芯片了,可以让他变成51,也可以是avr,甚至arm,同时SOPC是在SOC基础上来的,所以他也是系统级的芯片,所以记得当把他变成arm时还得加外围ROM,RAM之类的,不然就是MPU了。
中断和异常
中断是指外部硬件产生的一个电信号从CPU的中断引脚进入,打断CPU的运行。
异常是指软件运行过程中发生了一些必须作出处理的事件,CPU自动产生一个陷入来打断CPU的运行。异常在处理的时候必须考虑与处理器的时钟同步,实际上异常也称为同步中断,在处理器执行到因编译错误而导致的错误指令时,或者在执行期间出现特殊错误,必须靠内核处理的时候,处理器就会产生一个异常。
中断与DMA
DMA: 是一种无须CPU的参与,就可以让外设与系统内存之间进行双向数据传输的硬件机制,使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来,从而大大提高系统的吞吐率。
中断: 是指CPU在执行程序的过程中,出现了某些突发事件时,CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回源程序被中断的位置并继续执行。
所以中断和DMA的区别就是:DMA不需CPU参与,而中断是需要CPU参与的。
中断不能睡眠
中断处理的时候,不应该发生进程切换。因为在中断上下文中,唯一能打断当前中断handler的只有更高优先级的中断,它不会被进程打断。如果在中断上下文中休眠,则没有办法唤醒它,因为所有的wake_up_xxx都是针对某个进程而言的,而在中断上下文中,没有进程的概念,没有一个task_struct(这点对于softirq和tasklet一样)。因此真的休眠了,比如调用了会导致阻塞的例程,内核几乎肯定会死。
schedule()在切换进程时,保存当前的进程上下文(CPU寄存器的值、进程的状 态以及堆栈中的内容),以便以后恢复此进程运行。中断发生后,内核会先保存当前被中断的进程上下文(在调用中断处理程序后恢复)。但在中断处理程序里,CPU寄存器的值肯定已经变化了(最重要的程序计数器PC、堆栈SP等)。如果此时因为睡眠或阻塞操作调用了schedule(),则保存的进程上下文就不是当前的进程上下文了。所以,不可以在中断处理程序中调用schedule()。
2.4内核中schedule()函数本身在进来的时候判断是否处于中断上下文:
if(unlikely(in_interrupt()))
BUG();因此,强行调用schedule()的结果就是内核BUG,但看2.6.18的内核schedule()的实现却没有这句,改掉了。
中断handler会使用被中断的进程内核堆栈,但不会对它有任何影响,因为handler使用完后会完全清除它使用的那部分堆栈,恢复被中断前的原貌。
处于中断上下文时候,内核是不可抢占的。因此,如果休眠,则内核一定挂起。
中断的响应执行流程: cpu接受中断->保存中断上下文跳转到中断处理历程->执行中断上半部->执行中断下半部->恢复中断上下文。
写中断注意事项
写一个中断服务程序要注意快进快出,在中断服务程序里面尽量快速采集信息,包括硬件信息,然后退出中断,要做其它事情可以使用工作队列或者tasklet方式。也就是中断上半部和下半部。
中断服务程序中不能有阻塞操作。因为中断期间是完全占用CPU的(即不存在内核调度),中断被阻塞住,其他进程将无法操作。
中断服务程序注意返回值,要用操作系统定义的宏做为返回值,而不是自己定义的。
如果要做的事情较多,应将这些任务放在后半段(tasklet,等待队列等)处理。
虽然 tasklet 能帮你承载沉重的任务,但 tasklet 依然运行在中断上下文中(虽然是开中断状态)。这意味着下半部函数里绝对不允许睡眠、不允许调用信号量、不能使用可能阻塞的锁(如 mutex),只能使用自旋锁(spinlock)。如果任务重到必须要睡眠(比如需要等待输入输出、写磁盘等),那么应该使用 工作队列(Workqueue) 代替 tasklet。
中断和轮询
中断是CPU处于被动状态下来接受设备的信号,而轮询是CPU主动去查询该设备是否有请求。
如果是请求设备是一个频繁请求cpu的设备,或者有大量数据请求的网络设备,那么轮询的效率是比中断高。
如果是一般设备,并且该设备请求cpu的频率比较低,则用中断效率要高一些。主要是看请求频率。
通信协议
异步传输和同步传输
异步传输:是一种典型的基于字节的输入输出,数据按每次一个字节进行传输,其传输速度低。
同步传输:需要外界的时钟信号进行通信,是把数据字节组合起来一起发送,这种组合称之为帧,其传输速度比异步传输快。
RS232 & RS485
传输方式不同。 RS232采取不平衡传输方式,即所谓单端通讯。 而RS485则采用平衡传输,即差分传输方式。
传输距离不同。RS232适合本地设备之间的通信,传输距离一般不超过20m。而RS485的传输距离为几十米到上千米。
设备数量。RS232 只允许一对一通信,而RS485接口在总线上是允许连接多达128个收发器。
连接方式。RS232,规定用电平表示数据,因此线路就是单线路的,用两根线才能达到全双工的目的;而RS485, 使用差分电平表示数据,因此,必须用两根线才能达到传输数据的基本要求,要实现全双工,必需用4根线。
总结:从某种意义上,可以说,线路上存在的仅仅是电流,RS232/RS485规定了这些电流在什么样的线路上流动和流动的样式。
SPI
接口
- MOSI (Master Output, Slave Input) 主设备输出/从设备输入引脚。
- 主机的数据从这条信号线输出,从机由这条信号线读入主机发送的数据,即这条线上数据的方向为主机到从机。
- MISO(Master Input,, Slave Output)
- 主设备输入/从设备输出引脚。主机从这条信号线读入数据,从机的数据由这条信号线输出到主机,即在这条线上数据的方向为从机到主机。 3.
- SCLK (Serial Clock) 时钟信号线,用于通讯数据同步。
- 它由通讯主机产生,决定了通讯的速率,不同的设备支持的最高时钟频率不一样,如 STM32 的 SPI 时钟频率最大为fpclk/2, 两个设备之间通讯时,通讯速率受限于低速设备。
- SS( Slave Select) 从设备选择信号线,常称为片选信号线,也称为 NSS、 CS,以下用 NSS 表示。
- 当有多个 SPI 从设备与 SPI 主机相连时,设备的其它信号线 SCK、MOSI 及 MISO 同时并联到相同的 SPI 总线上,即无论有多少个从设备,都共同只使用这 3 条总线;而每个从设备都有独立的这一条 NSS 信号线,本信号线独占主机的一个引脚,即有多少个从设备,就有多少条片选信号线。 I2C 协议中通过设备地址来寻址、选中总线上的某个设备并与其进行通讯;而 SPI 协议中没有设备地址,它使用 NSS 信号线来寻址,当主机要选择从设备时,把该从设备的 NSS 信号线设置为低电平,该从设备即被选中,即片选有效,接着主机开始与被选中的从设备进行 SPI 通讯。所以SPI 通讯以 NSS 线置低电平为开始信号,以 NSS 线被拉高作为结束信号。
CPOL(时钟极性)/CPHA(时钟相位)及通讯模式
时钟极性 CPOL 是指 SPI 通讯设备处于空闲状态时, SCK 信号线的电平信号(即 SPI 通讯开始前、 NSS 线为高电平时 SCK 的状态)。 CPOL=0 时, SCK 在空闲状态时为低电平,CPOL=1 时,则相反。
时钟相位 CPHA 是指数据的采样的时刻,当 CPHA=0 时, MOSI 或 MISO 数据线上的信号将会在 SCK 时钟线的“奇数边沿” 被采样。当 CPHA=1 时, 数据线在 SCK 的“偶数边沿” 采样。
IIC
IIC协议是由数据线SDA和时钟SCL构成的串行总线,可发送和接收数据,是一个多主机的半双工通信方式
每个挂接在总线上的器件都有个唯一的地址。位速在标准模式下可达 100kbit/s,在快速模式下可达400kbit/s,在高速模式下可到3.4Mbit/s。
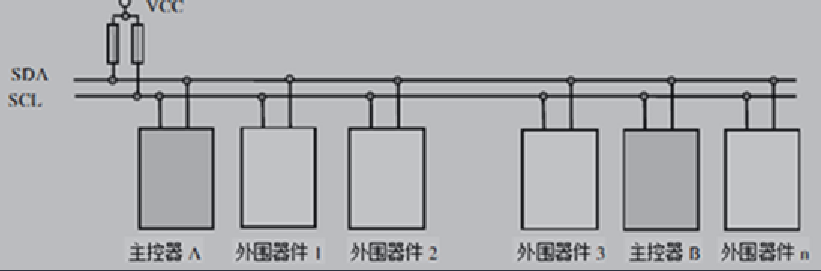
IIC时序
空闲状态: 当总线上的SDA和SCL两条信号线同时处于高电平,便是空闲状态,如上面的硬件图所示,当我们不传输数据时, SDA和SCL被上拉电阻拉高,即进入空闲状态
起始信号: 当SCL为高期间,SDA由高到低的跳变;便是总线的启动信号,只能由主机发起,且在空闲状态下才能启动该信号,如下图所示:
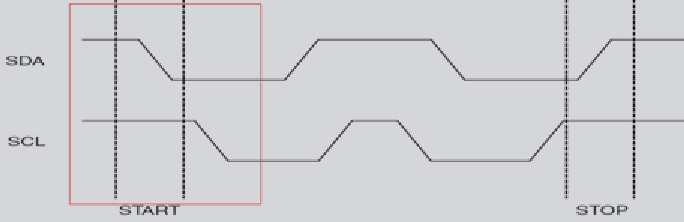
停止信号: 当SCL为高期间,SDA由低到高的跳变;便是总线的停止信号,表示数据已传输完成, 如下图所示:
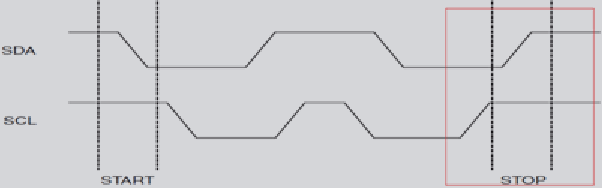
传输数据格式: 当发了起始信号后,就开始传输数据,传输的数据格式如下图所示: 当SCL为高电平时,便会获取SDA数据值,其中SDA数据必须是稳定的(若SDA不稳定就会变成起始/停止信号)。当SCL为低电平时,便是SDA的电平变化状态。若主从机在传输数据期间,需要完成其它功能(例如一个中断),可以主动拉低SCL,使I2C进入等待状态,直到处理结束再释放SCL,数据传输会继续
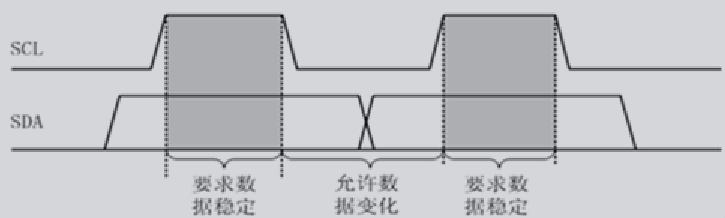
应答信号ACK: I2C总线上的数据都是以8位数据(字节)进行的,当发送了8个数据后,发送方会在第9个时钟脉冲期间释放SDA数据,当接收方接收该字节成功,便会输出一个ACK应答信号,当SDA为高电平,表示为非应答信号NACK,当SDA为低电平,表示为有效应答信号ACK。当主机为接收方时,收到最后一个字节后,主机可以不发送ACK,直接发送停止信号来结束传输。当从机为接收方时,没有发送ACK,则表示从机可能在忙其它事、或者不匹配地址信号和不支持多主机发送,主机可以发送停止信号,再次发送起始信号启动新的传输。
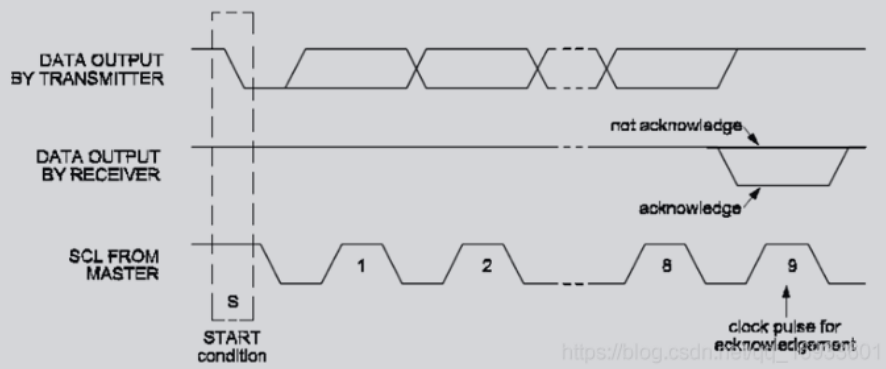
完整的数据传输: 如下图所示, 发送起始信号后,便发送一个8位的设备地址,其中第8位是对设备的读写标志,后面紧跟着的就是数据了,直到发送停止信号终止。PS:当我们第一次是读操作,然后想换成写操作时,可以再次发送一个起始信号,然后发送读的设备地址,不需要停止信号便能实现不同的地址转换。
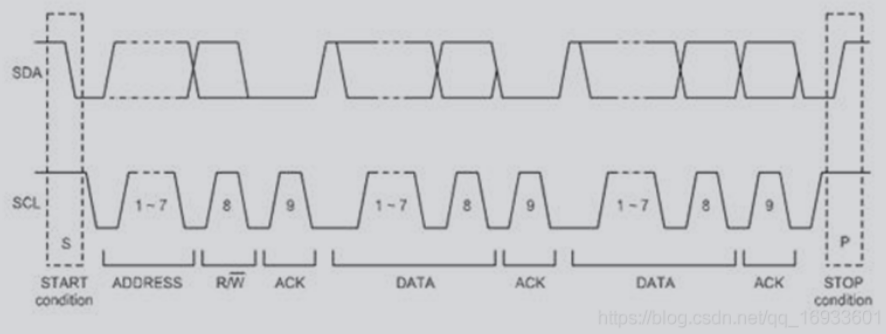
IIC传输数据格式
写操作
刚开始主芯片要发出一个start信号,然后发出一个(用来确定是往哪一个芯片写数据),方向(读/写,0表示写,1表示读)。回应(用来确定这个设备是否存在),然后就可以传输数据,传输数据之后,要有一个回应信号(确定数据是否接受完成),然后再传输下一个数据。每传输一个数据,接受方都会有一个回应信号,数据发送完之后,主芯片就会发送一个停止信号。 白色背景:主→从。灰色背景:从→主。
读操作
刚开始主芯片要发出一个start信号,然后发出一个设备地址(用来确定是从哪一个芯片读取数据),方向(读/写,0表示写,1表示读)。回应(用来确定这个设备是否存在),然后就可以传输数据,传输数据之后,要有一个回应信号(确定数据是否接受完成),然后在传输下一个数据。每传输一个数据,接受方都会有一个回应信号,数据发送完之后,主芯片就会发送一个停止信号。 白色背景:主→从。灰色背景:从→主
常用linux指令
常用GDB指令
gcc -g test.c -o test #编译时生成debug有关的程序信 |
uboot
bootloader
Linux系统要启动就必须需要一个 bootloader程序,也就说芯片上电以后先运行一段bootloader程序。这段 bootloader程序会先初始化时钟,看门狗,中断,SDRAM,等外设,然后将 Linux内核从 flash(NAND, NOR FLASH,SD,MMC等)拷贝到SDRAM中,最后启动Linux内核。当然了, bootloader的实际工作要复杂的多,但是它最主要的工作就是启动 Linux内核。bootloader和 Linux内核的关系就跟PC上的BIOS和 Windows的关系一样,bootloader就相当于BIOS。总得来说,Bootloader就是一小段程序,它在系统上电 时开始执行,初始化硬件设各、准备好软件环境,最后调用操作系统内核。
uboot启动过程
- 第一阶段
- 初始化时钟,关闭看门狗,关中断,启动ICACHE,关闭DCACHE和TLB,关闭MMU,初始化SDRAM,初始化NAND FLASH,重定位。
- 第二阶段
- 初始化一个串口,检测系统内存映射,将内核映象和根文件系统映象从 Flash上读到SDRAM空间中,为内核设置启动参数,调用内核。
uboot和内核的参数传递
通过直接修改PC寄存器的值为Linux内核所在的地址,uboot跳转到linux内核所在的地址运行。这样CPU就会从Linux内核所在的地址去取指令,从而执行内核代码
在跳转到内核以前,uboot需要做好以下三件事情:
(1) CPU寄存器的设置 R0=0 R1=机器类型ID;对于ARM结构的CPU,其机器类型ID可以参见 linux/arch/armtools/ mach-types R2=启动参数标记列表在RAM中起始基地址
(2) CPU工作模式 必须禁止中断(IRQs和FIQs) CPU必须为SVC模式
(3) Cache和MMU(Memory Management Unit)的设置 MMU必须关闭指令 Cache可以打开也可以关闭。数据 Cache必须关闭,其中上面第一步CPU寄存器的设置中,就是通过R0,R1,R2三个参数给内核传递参数的。
文件系统
可执行镜像文件的构成
- 一个或多个代码段,代码段的属性为只读。
- 零个或多个包含初始化数据的数据段,数据段的属性为可读写。
- 零个或多个不包含初始化数据的数据段,数据段的属性为可读写。
硬中断和软中断
硬中断
硬中断是由硬件产生的,比如,像磁盘,网卡,键盘,时钟等。每个设备或设备集都有它自己的IRQ(中断请求)。基于IRQ,CPU可以将相应的请求分发到对应的硬件驱动上(注:硬件驱动通常是内核中的一个子程序,而不是一个独立的进程)。
处理中断的驱动是需要运行在CPU上的,因此,当中断产生的时候,CPU会中断当前正在运行的任务,来处理中断。在有多核心的系统上,一个中断通常只能中断一颗CPU(也有一种特殊的情况,就是在大型主机上是有硬件通道的,它可以在没有主CPU的支持下,可以同时处理多个中断。)。
硬中断可以直接中断CPU。它会引起内核中相关的代码被触发。对于那些需要花费一些时间去处理的进程,中断代码本身也可以被其他的硬中断中断。
对于时钟中断,内核调度代码会将当前正在运行的进程挂起,从而让其他的进程来运行。它的存在是为了让调度代码(或称为调度器)可以调度多任务。
软中断
软中断的处理非常像硬中断。然而,它们仅仅是由当前正在运行的进程所产生的。
通常,软中断是一些对I/O的请求。这些请求会调用内核中可以调度I/O发生的程序。对于某些设备,I/O请求需要被立即处理,而磁盘I/O请求通常可以排队并且可以稍后处理。根据I/O模型的不同,进程或许会被挂起直到I/O完成,此时内核调度器就会选择另一个进程去运行。I/O可以在进程之间产生。并且调度过程通常和磁盘I/O的方式是相同。
软中断仅与内核相联系。而内核主要负责对需要运行的任何其他的进程进行调度。一些内核允许设备驱动的一些部分存在于用户空间,并且当需要的时候内核也会调度这个进程去运行。
软中断并不会直接中断CPU。也只有当前正在运行的代码(或进程)才会产生软中断。这种中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求。有一个特殊的软中断是Yield调用,它的作用是请求内核调度器去查看是 否有一些其他的进程可以运行。
区别
- 软中断是执行中断指令产生的,而硬中断是由外设引发的。
- 硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。
- 硬中断是可屏蔽的,软中断不可屏蔽。
- 硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。
- 软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。
为什么要区别上半部分和下半部分
Linux中断分为硬件中断和内部中断(异常),调用过程:外部中断产生->发送中断信号到中断控制器->通知处理器产生中断的中断号,让其进一步处理。对于中断上半部和下半部的产生,为了中断处理过程中被新的中断打断,将中断处理一分为二,上半部登记新的中断,快速处理简单的任务,剩余复杂耗时的处理留给下半部处理,下半部处理过程中可以被中断,上半部处理时不可被中断。
- 中断下半部分一般通过软中断、tasklet、工作队列实现
中断的响应流程:cpu接受中断->保存中断上下文跳转到中断处理历程->执行中断上半部->执行中断下半部->恢复中断上下文。
中断的申请request_irq的正确位置:应该是在第一次打开 、硬件被告知中断之前。
 支付宝
支付宝
